22.07. Pitch: LLM-based Research Assistant¶
In the final pitch, the contractors will present their solution to automated research hypothesis generation and validation. The solution will have to introduce a multi-agent environment to conduct collaborative research tasks with built-in verification and conflict resolution mechanisms. The solution will read and analyze research literature, generate hypotheses, and validate findings through agent collaboration. The research domain is linguistics so we can evaluate the quality of the generations better.
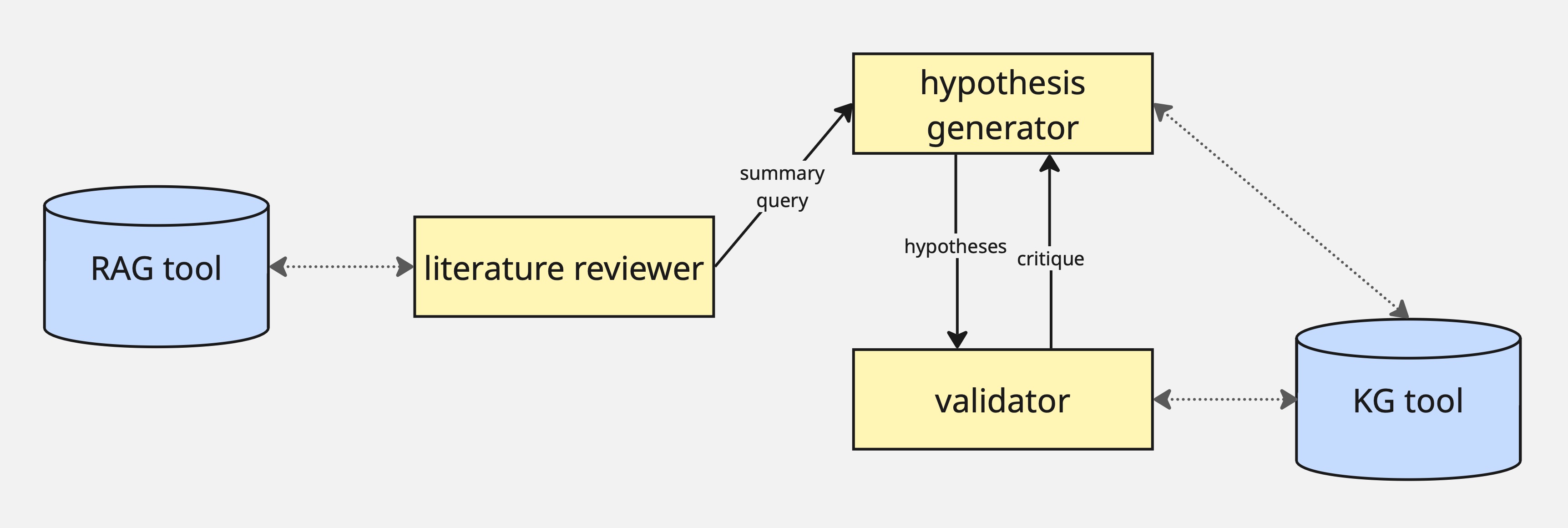
The initial idea to the architecture of this multi-agent system is the following:
There are 3 agents:
The literature reviewer processes and summarizes research papers, extracts key claims, methodologies, and findings, and identifies citation networks and paper relationships
The hypothesis generator generates research hypotheses based on literature gaps using cross-domain analogy generation techniques, proposes multiple competing hypotheses with reasoning, and ranks them by novelty and feasibility
The validator evaluates hypotheses for logical consistency, challenges assumptions and identifies missing evidence, and provides constructive feedback for hypothesis refinement
Once a new research question comes, the literature reviewer is triggered; it processes relevant papers and forms a structured analysis for the hypothesis generator
Once the hypothesis generator receives the analysis, it generates multiple hypotheses and sends them with reasoning to the validator; the hypothesis generator has an access to a ool to query a linguistic knowledge graph (KG) for entities and relations
Validator has the KG tool as well; if the hypotheses contradict the graph or is just not reliable, it sends feedback back to the hypothesis generator for refinement, otherwise approves it
Once hypotheses are approved by the validator, they are returned to the user
Now once again, we will not add any actual integrations but rather simulate them, which the agent will not be aware of. All they will know is that these tools are provided and which scheme they conform to.
Obviously, in a real product, such research process would run with actual research databases. However, this functionality is not relevant for us, so we will once again simulate it with a synthetic literature collection. Also, the knowledge graph is usually not static and is updated as the system evolves, which will not be the case for this project.
As always, you don’t have to strictly follow this scheme, it is just a quick start suggestion for you, you may change it as you want.
Task¶
The project folder has the following structure:
The
resourcesfolder contains sample research abstracts and domain knowledge about linguistics generated with Claude. You will use it to simulate the literature base for the agents.The
multi_agentfolder folder will store the implementation of your system.tools.pywill contain the tools for your agents. It now contains a single tool for querying KG but you may want to add a RAG tool for literature in case you want it more custom than the standard LangChain implementation or if you choose another framework.prompts.pywill contain the prompts for your system.agents.pywill implement the multi-agent system.
demo.ipynbwill showcase the capabilities and the limitations of the resulting system. It will take the initialized multi-agent system frommulti_agent/agents.pyand run it with different research questions.
Your task is to fill in the code in the provided boilerplates following the instructions below.
You may use any LLM and any orchestration framework you like.
You are free in your implementation as long as it follows the architectural constrains (implements a suggested or your version of a multi-agent system).
You don’t have to strictly follow the boilerplate, it is just a quick start suggestion; if you think it fits your solution better, feel free to remove/edit the suggested functions as well as add your. The only limitation you have here is that the solution should be written as Python scripts (not a notebook!), and it should be called from
demo.ipynb.
You don’t have to find a perfect solution, imagine you are building an initial baseline; this activity is more about detecting the limitations and vulnerabilities of your own work and suggesting the ways to improve. Most importantly, you have to be able to explain your design choices and justify them for this particular use case.
Steps¶
Setup¶
Download the project folder.
Go through the usual setup routine to setup your environment for the project. Put the resulting
requirements.txtfile with the dependencies in the project folder.
Knowledge Graph Tools in multi_agent/tools.py¶
Knowledge Graph Query Tool (
knowledge_graph_query())
Write a tool to query the knowledge graph for fact-checking and validation.
Should support queries for entity relationships, confidence scores, and contradictions.
Return relevant graph information for validation purposes.
(Optional) RAG Tool
If you want it more custom RAG tool the standard LangChain implementation or if you choose another framework for orchestration, put your RAG tool here.
It should extract relevant literature fragments from the literature base in
litbase.md.
Prompts in multi_agent/prompts.py¶
Here, you will be adding the prompts you will find required for your implementation.
Multi-agent System in multi_agent/agents.py¶
Complete the ResearchLaMA class as follows:
Initialization (
__init__())
Initialize your LLM.
Initialize the four agents (literature reviewer, hypothesis generator, validator).
Initialize the knowledge graph and orchestration system.
Replace the placeholder for the keyword arguments (
**kwargs) with specific parameters that you need to initialize the agent (or none, if none is needed).
Invoke the Literature Reviewer (
literature_reviewer_node())
Extract the most relevant papers from the literature base in
litbase.md.Generate a summary with key information, findings, theories etc.
Invoke the Hypothesis Generator (
hypothesis_generator_node())
Generate multiple research hypotheses based on retrieved literature.
Generate confidence to the hypotheses.
Invoke the Validator Agent (
validator_node())
Fact-check hypotheses against knowledge graph.
(Re)assign confidence scores to generated content.
Generate feedback if the hypotheses should be regenerated.
Refine Hypotheses (
refine_hypotheses())
Have the hypothesis generator refine the hypotheses based on the feedback from the validator.
Agent Run (
run())
Route the input through the steps.
Ensure the transparent output: current steps, reasoning, validation result etc.
Additional notes:
If you will be using
LangGraphas the orchestration framework, create a state scheme and replace the individual parameters in the functions with thestateparameter.Build the routing logic in a separate function according to your framework (e.g. specify edges and nodes for
LangGraph).Once again, you may add/edit anything you want as long as it creates a multi-agent system.
Demonstration in demo.ipynb¶
Define the parameter values you need for instantiating the ResearchLaMA class from multi_agent/agents.py and initialize it. Run the agent with different research questions – it should demonstrate the complete pipeline from literature analysis through hypothesis generation, criticism, and validation.
Deliverables & Logistics¶
Prepare slides that would present your solution to the “company board” (your fellow students). The slides should highlight the design decisions step by step (agent initialization, multi-agent pipeline, knowledge graph integration, etc.), explain the choices of the LLMs, orchestration framework, and conflict resolution mechanisms, so basically justify why you implemented the system the way you did. It should then inspect the outputs of the system in detail and provide a qualitative analysis of the research hypotheses generated, their novelty, feasibility, and validation quality. Finally, it should discuss the current limitations and possible workarounds.
With these slides, you will hold a presentation (30-40 min). After that, you have to be ready to answer the questions from the board.
Put the complete code and the slides to a GitHub repository. It may be private if you want, then you will have to send an invitation for the username
maxschmaltz. The submission succeeds via email, and the deadline is July 22, 12pm. Note: if you will put the files to the repo manually, don’t forget to exclude environment variables, dependencies etc.